
El análisis exploratorio de datos es una parte fundamental de cualquier proceso de análisis de datos o ciencia de datos. Antes de que un científico de datos se sumerja en responder preguntas con datos, necesita saber algo sobre los datos con los que está trabajando. Saber cómo hacer un análisis exploratorio de datos con Python le permitirá brindarle a su equipo de datos una vista inicial de los datos disponibles.
En este artículo, revisaremos lo que significa realizar un análisis exploratorio de datos con Python y luego veremos los dos tipos de datos: categóricos y numéricos. Para cada uno, consideraremos dos categorías principales de análisis de datos exploratorios: gráficos y no gráficos.
Contenido
¿Qué es el análisis exploratorio de datos?
Mucha gente que viaja a una nueva ciudad explorará al llegar mirando un mapa o caminando y conduciendo para tener una idea de los principales puntos de referencia. Pueden pasar tiempo buscando cosas interesantes como restaurantes, parques, etc. para tener una idea de lo que la ciudad tiene reservado para ellos una vez que profundicen.
El análisis exploratorio de datos es un proceso similar cada vez que obtenemos un nuevo conjunto de datos: queremos obtener una vista de alto nivel de los datos, así como navegar un poco y ver qué puede ser interesante. Hacemos esto con una combinación de herramientas gráficas y no gráficas.
Lo más interesante que queremos aprender sobre datos categóricos es resumir recuentos de valores de datos. Para datos numéricos, las cosas interesantes incluyen encontrar el centro, la dispersión y la forma de la distribución de valores. En las secciones a continuación, veremos los dos tipos diferentes de datos descritos aquí utilizando métodos gráficos y no gráficos.
Data de muestra.
En las siguientes secciones, utilizaremos una muestra de datos descargados de Kaggle Datasets. Específicamente, estamos viendo los datos de 2013 que se encuentran en el archivo 2013.csv.
Datos categóricos.
A veces, los datos representan categorías de elementos y, a veces, se denominan datos categóricos o cualitativos. Los ejemplos incluyen el nivel educativo («diploma de escuela secundaria», «licenciatura», «título de posgrado»); color de cabello («marrón», «negro», «rubio», «rojo»); o incluso condiciones binarias como el estado actual del cliente («sí», «no»).
Las características de interés para los datos categóricos al realizar un análisis exploratorio de datos con Python incluyen el rango de valores, así como la frecuencia o la duplicación/exclusividad de los valores. Veamos algunas formas no gráficas de explorar estas características.
Métodos no gráficos.
Una de las primeras cosas que podríamos querer hacer con un conjunto de datos es tener una idea de la forma de los datos (número de filas x número de columnas), así como obtener una lista de los nombres de las columnas. El siguiente código hace esto por nosotros. Este conjunto de datos tiene más de 6 millones de filas de datos y 28 columnas.
# Shape of the data frame and column headers
display(df.shape)
display(list(df.columns))

A continuación, veamos algunos de los campos categóricos. OP_CARRIER es la abreviatura de la aerolínea y ORIGIN y DEST son los códigos de aeropuerto inicial y final para cada vuelo en el conjunto de datos. Todos estos son campos de datos categóricos. Esta línea de código imprimirá el rango de valores para el OP_CARRIER campo.
# Show values in some categorical columns
display(df['OP_CARRIER'].unique())

Ahora que conocemos el rango de valores, averigüemos cuántos de cada uno hay en el conjunto de datos. Recuerde, hay más de 6 millones de filas de datos, ¡así que esperamos mucha duplicación aquí! Esta línea de código muestra cómo obtener el recuento de valores duplicados en el OP_CARRIER columna. La primera columna de los resultados es la OP_CARRIER código y la segunda columna es el número de duplicados de ese valor.
# Find duplicates
df['OP_CARRIER'].value_counts()

En lugar de solo usar los recuentos sin procesar, también podemos calcular fácilmente qué porcentaje de la columna total representa cada valor usando el parámetro «normalizar». El siguiente código demuestra esta técnica.
# Find percentage of total
df['OP_CARRIER'].value_counts(normalize=True)

Las técnicas anteriores nos permiten tener una idea rápida y sencilla de los tipos de valores en columnas categóricas, así como tener una idea de los recuentos de estos valores.
Métodos gráficos.
Los gráficos y cuadros nos permiten visualizar datos de formas más intuitivas que un simple texto. Una de las mejores formas de ver gráficamente los datos categóricos es mediante un gráfico de barras. Por ejemplo, en el último paso anterior, imprimimos una lista de recuentos duplicados. El siguiente código traza estos recuentos de mayor a menor para que podamos comparar los resultados más fácilmente.
# Bar graph of value counts
df['OP_CARRIER'].value_counts().plot(kind='bar')

Puede ver cómo obtenemos la misma información tanto del texto como de las representaciones gráficas, pero el gráfico facilita ver la «forma» de los datos. Ya sea que estemos usando texto o representaciones gráficas, el objetivo del análisis exploratorio de datos categóricos usando Python es tener una idea de los valores y conteos de valores en el conjunto de datos.
Datos numéricos.
Los datos representados por números a veces se denominan datos cuantitativos o numéricos. Estos números a veces representan recuentos simples (como vimos con los datos categóricos), pero también pueden ser variables continuas donde los valores se encuentran en un rango.
Los ejemplos de este tipo de datos incluyen valores comunes como la altura, el peso, los totales de ventas, el tiempo y la distancia recorrida. Los valores de datos numéricos aparecen en casi todos los dominios, por lo que es útil aprender a explorar este tipo de datos.
Las características de interés para los datos cuantitativos o numéricos incluyen medidas de centralidad, dispersión y forma de distribución. Las medidas de centralidad nos dicen dónde se centran los valores en los datos. La medida más común es la media o promedio. Otra medida común es el valor mediano o medio de los datos. Spread se refiere a qué tan variados son los valores en el conjunto de datos. ¿La mayoría de los valores están agrupados en torno a un pequeño conjunto de valores o están repartidos en un amplio rango? Esto está relacionado con la forma de la distribución y aquí, las medidas de sesgo y curtosis nos brindan detalles importantes sobre cómo se distribuyen los valores en el rango de valores. Veamos algunas formas de explorar datos numéricos.
Métodos no gráficos.
Una forma sencilla de obtener una vista no gráfica de su conjunto de datos en pandas es usar el describe() método en su marco de datos. Este método producirá varias estadísticas descriptivas interesantes para todas las columnas numéricas. Éstos incluyen:
- Count: un recuento de valores no vacíos en la columna
- Media: el valor promedio de la columna.
- Std: desviación estándar (una medida estadística de la dispersión de los datos)
- Min, Max: los valores más bajo y más alto de la columna
- 25 %, 50 %, 75 %: los valores que representan el rango percentil dentro de la columna
Estas son medidas comunes que la mayoría de los estadísticos aplicados pueden escanear rápidamente para tener una idea de los datos con los que van a trabajar.
Aquí está el código y un fragmento de la salida para el conjunto de datos.
#Describe the numerical columns
df.describe()

Si bien esta información es útil, el sesgo y la curtosis a menudo son útiles para que los estadísticos aplicados tengan una idea de la forma de la distribución. Por sí mismos, los números pueden no ser significativos si no tiene experiencia en estadística, pero son números simples para calcular usando pandas (y veremos representaciones visuales de estos valores a continuación). Aquí está el código para calcular los valores :
#Skew and Kurtosis
df['ACTUAL_ELAPSED_TIME'].skew()
df['DEP_TIME'].skew()
df['ACTUAL_ELAPSED_TIME'].kurtosis()
df['DEP_TIME'].kurtosis()
Métodos gráficos.
Una de las formas más útiles de visualizar datos numéricos es el histograma. Este gráfico recopila valores que son similares entre sí en «contenedores» y luego representa gráficamente la frecuencia relativa de los valores que caen dentro de cada contenedor. El siguiente código muestra los histogramas de las dos columnas para las que calculamos el sesgo y la curtosis anteriormente:
#Histograms
df['ACTUAL_ELAPSED_TIME'].hist(bins=50)

df['DEP_TIME'].hist(bins=24)
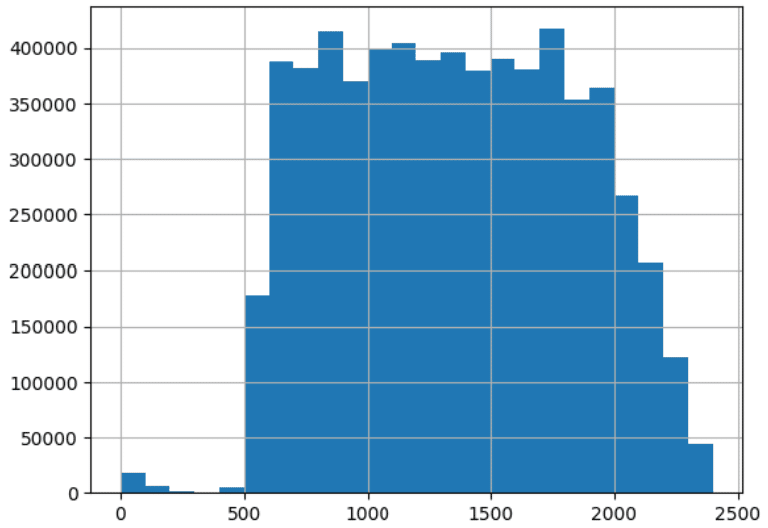
Observe cómo los gráficos muestran una forma diferente para la distribución de valores. Compare estas formas con los valores calculados anteriormente para sesgo y curtosis. Una de las mejores formas de obtener una idea intuitiva de lo que significan estos términos es calcular los números y luego generar un histograma y compararlos. Además, observe que el histograma nos brinda una representación visual tanto de la tendencia central como de la dispersión. Estos gráficos tienen un valor incalculable para un ingeniero de datos que realiza un análisis exploratorio de datos con Python.
Otro gráfico poderoso para visualizar datos numéricos es el gráfico de diagrama de caja. Este gráfico combina los números medios y percentiles que vimos del método descrito con una demostración visual de los valores atípicos. Los valores atípicos son puntos de datos que están anormalmente lejos del centro de los datos. El siguiente código muestra el diagrama de caja de la TAXI_OUT columna.
#Box plot
df.boxplot(column=['TAXI_OUT'])

En conclusión.
En este artículo, hemos examinado datos categóricos y numéricos y hemos explorado métodos gráficos y no gráficos para realizar análisis exploratorios de datos utilizando Python. Estos métodos lo ayudarán a comenzar a proporcionar información valiosa para científicos de datos y estadísticos que esperan usar los datos que está preparando para ellos.
¿Listo para intensificar sus habilidades de ingeniería de datos? Aprende a codificar con Udacity.
El análisis exploratorio de datos con Python es una habilidad fundamental para cualquier ingeniero de datos en un entorno moderno de ciencia de datos. En este artículo, explicamos lo que significa realizar un análisis exploratorio de datos y luego exploramos métodos no gráficos y gráficos para explorar datos categóricos y numéricos.
Nuestro programa Programación para ciencia de datos con Python Nanodegree es su próximo paso. Te enseñaremos a trabajar en el campo de la ciencia de datos utilizando las herramientas fundamentales de programación de datos: Python, SQL, línea de comandos y git.
COMIENZA A APRENDER